3667 views
1.はじめに
ちょっと仕事でテキスト分類ができたら作業効率上がりそうだな―という件があり、やってみることにしました。
単語のベクトル変換とか、時系列でごにょごにょとかそんなのはどうでもよくて、とりあえず、そこそこの精度で動かせて、それが実務レベルでどのくらい役に立ちそうか検証したいだけの方向けの記事です。
2. 対象読者
分かち書きが理解できて、pythonが理解できて、ubuntuの操作ができるくらいの人向け。
3. 試した環境
・virtualbox上のubuntu18.04。ごついGPUとかなくてもサクサク動きました。
・python3
使用する分類器
テキスト分類はfacebookが公開してくれている、fasttextをありがたく使用させていただきます。
分かち書きは、お約束のmecab。
4. インストール
fasttextを動作させるために必要な設定について記します。
4.1 fasttextのインストール
以下を実行して、fasttextをインストールします。かなり簡単です。
git clone https://github.com/facebookresearch/fastText.git
cd fastText
pip3 install .
4.2 mecabのインストール
分かち書きをするためのmecabをインストールします。
sudo apt install mecab libmecab-dev mecab-ipadic-utf8
pythonから呼び出せるように、mecab-python3をインストールします。
pip3 install mecab-python3
これでfasttextを使う環境が整いました。
5. 動かし方
今回は、ニュース分類を行うプログラムを作って動かし方を説明します。
今回作成するニュース分類プログラムでは、与えられたネットニュースの記事を「地域」「経済」「エンタメ」「政治」「国際」「IT」「生活」「国内」「科学」「スポーツ」の10個のカテゴリーの中のどれに最も近い内容かをfasttextが予測します。
まず、fasttextがニュースを分類できるようにするには、学習データを与えてトレーニングさせる必要があります。
学習データをそのままfasttextに与えることができない(そういう仕様)ので、いったんfasttextが理解しやすいように学習データを加工します。
次に、加工した学習データをfasttextに与えて学習させます。
学習が終わると、fasttextは重みファイルを出力します。重みファイルとは、AIの脳みそみたいなものです。
最後に、重みファイルを使って、トレーニングには使用していないテキストを判定させて予測させます。
これからやることをまとめると、
1.データの前処理(pretrain)
2.学習データを使ってfasttextをトレーニング(train)
3.トレーニングした重みファイルを使って、トレーニングに使用していないニュースを予測、分類させる(predict)
です。
サンプルプログラムのファイル構成を以下に記します。
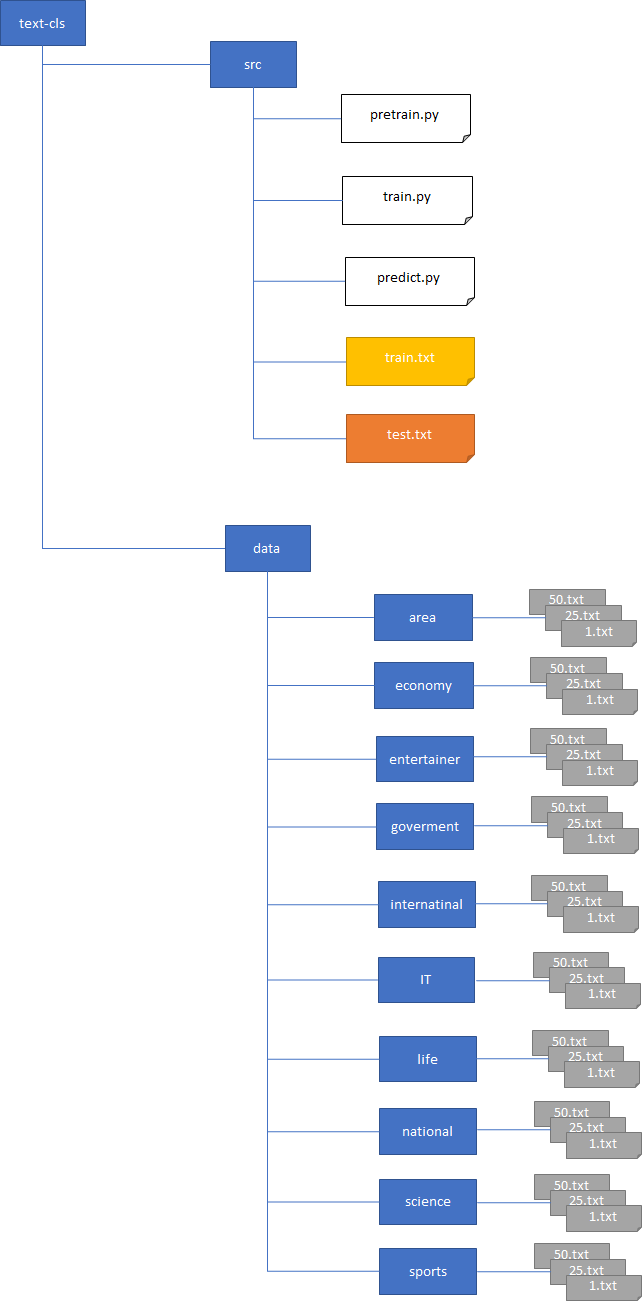
text-clsディレクトリの下にsrcディレクトリとdataディレクトリがあります。各ファイルの内容について以下に記します。
| ディレクトリ/ファイル名 | 説明 |
|---|---|
| src/pretrain.py | fasttextが学習しやすいようにデータを加工するプログラム |
| src/train.py | fasttextが学習するプログラム |
| src/predict.py | fasttextが予測するプログラム |
| src/train.txt | pretrain.pyで作成するトレーニング用の学習データ |
| src/test.txt | pretrain.pyで作成するテスト用の学習データ |
| data/area | 「地域」に関する学習データを1.txt~N.txt個格納する。図は50個くらい |
| data/economy | 「経済」に関する学習データを1.txt~N.txt個格納する。図は50個くらい |
| data/entertainer | 「エンタメ」に関する学習データを1.txt~N.txt個格納する。図は50個くらい |
| data/government | 「政治」に関する学習データを1.txt~N.txt個格納する。図は50個くらい |
| data/internatinal | 「国際」に関する学習データを1.txt~N.txt個格納する。図は50個くらい |
| data/IT | 「IT」に関する学習データを1.txt~N.txt個格納する。図は50個くらい |
| data/national | 「国内」に関する学習データを1.txt~N.txt個格納する。図は50個くらい |
| data/science | 「科学」に関する学習データを1.txt~N.txt個格納する。図は50個くらい |
| data/sports | 「スポーツ」に関する学習データを1.txt~N.txt個格納する。図は50個くらい |
5.1 pretrain
src/[カテゴリ]の下にあるファイルは、ニュースサイトからコピーしてきた、ただのテキストファイルです。各カテゴリにふさわしい記事を記事ごとにtxtファイルに保存します。図では、1.txt,25.txt,50.txtとなっていますが、拡張子がtxtであれば大丈夫で、txtファイルの数は何個でもよいです。多いほど良いですが、全体的にカテゴリごとに同じ数くらいになるのが良いかと思います。
各ファイルから読みだしたテキストは、次の書式に変換したものをfasttextに与える必要があります。本記事では、以下の内容をtrain.txtとtest.txtにpretrain.pyで作成しています。
__label__カテゴリ名△,△分かち書き文字列△・・・△分かち書き文字列⏎
__label__カテゴリ名△,△分かち書き文字列△・・・△分かち書き文字列⏎
__label__カテゴリ名△,△分かち書き文字列△・・・△分かち書き文字列⏎
・
・
・
__label__カテゴリ名△,△分かち書き文字列△・・・△分かち書き文字列⏎
△は半角スペース、行末は改行。
変換プログラムを以下に記します。
変換プログラムでは、10分の8の確率でtrain.txtに、10分の2の確率でtest.txtに学習データを書き込みます。なお、test.txtは学習には用いず、学習したfasttextがどのくらいの認識率になっているかをテストするために使用します。
# coding:UTF-8
import glob
import os
import MeCab
import random
DATA_PATH = r'../data'
TRAIN_FILE = './train.txt'
TEST_FILE = './test.txt'
'''
10分の8の確率でテスト用ファイルにデータを書き込む
'''python
def fasttext_file(record):
r = random.randint(1, 10)
filename = TRAIN_FILE
if r > 8:
filename = TEST_FILE
with open(filename, 'a') as f:
f.write(record)
if __name__ == '__main__':
if os.path.exists(TEST_FILE):
os.remove(TEST_FILE)
if os.path.exists(TRAIN_FILE):
os.remove(TRAIN_FILE)
m = MeCab.Tagger('-Owakati')
# ../dataの下ディレクトリ一覧を取得する
dir_list = glob.glob(os.path.join(DATA_PATH, "*"))
for category_number, dir_name in enumerate(dir_list):
# カテゴリ名にディレクトリの名前を使う
category_name = dir_name.split("/")[-1]
print("category:{}".format(category_name))
#テキストファイル一覧取得
file_list = glob.glob(os.path.join(dir_name,"*.txt"))
for file_name in file_list:
with open(file_name, "r", encoding="sjis") as f:
try:
text = f.read()
# 改行と\u3000を除去して一行の文字列にする。
text = text.replace("\r\n", "")
text = text.replace("\n", "")
text = text.replace("\u3000", "")
#mecabで単語区切りにする
text = m.parse(text)
# fasttextが求める書式に直す
record = '__label__{} , {}'.format(category_name, text)
fasttext_file(record)
except:
# 文字コード変換でエラーになったファイルは無視する
#print(text)
print("error")
5.2 train
pretrain.pyで作成したtrain.txtでfasttextを学習させ、学習したfasttextの精度がどのくらいになっているかをtest.txtを使って計測します。
サンプルコードを以下に記します。
# coding:UTF-8
import fasttext as ft
import random
import os
if __name__ == '__main__':
model = ft.train_supervised(input="train.txt", epoch=1000, loss="hs")
model.save_model("fasttext.model")
results = model.test("test.txt")
print(results)
アホみたいに簡単です。
ft.trainsupervised(input="train.txt", epoch=1000, loss="hs")
で、train.txtを読み込んで学習し、学習が完了したら、
model.savemodel("fasttext.model")
でモデルファイルを保存します。
さらに、
results = model.test("test.txt")
にtest.txtを使って予測させ、ラベルとの一致の割合を見ます。
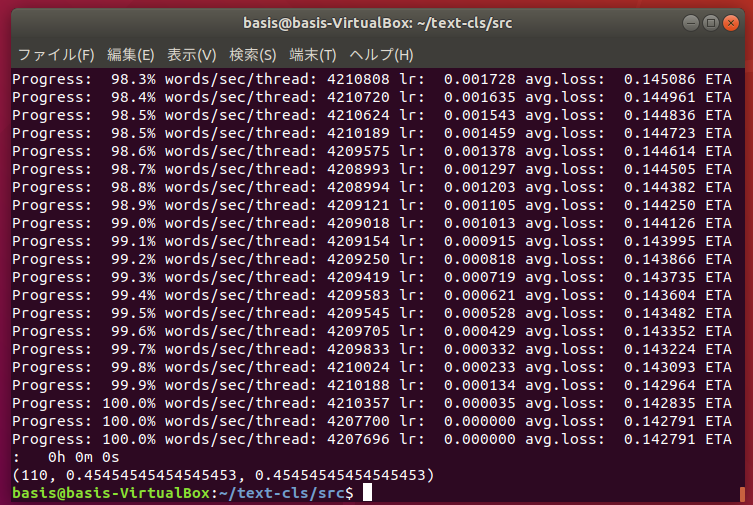
学習データが各カテゴリ50ファイルくらいだと、こんなもん・・・?だいぶ精度が低いですが、まぁ、まずは動かないことにはどうしようもないので、このあたりは今回はこだわりません。
#実験結果を見た感じ、政治と国際、生活と国内の分別があまりついてないような感じでした。
#スポーツ、ITは結構うまく分類できているっぽいので、与えたデータがダメだったのかもしれません
5.3 predict
学習が終わったので、次は予測です。
サンプルプログラムを以下に記します。
カレントにtrain.pyで生成したfasttext.modelを読み込み、同じくカレントにあるpredict.txtを読み込み、レコードを分かち書きにして予測させています。
# coding:UTF-8
import fasttext as ft
import MeCab
if __name__ == '__main__':
cls = ft.load_model('fasttext.model')
m = MeCab.Tagger('-Owakati')
with open("predict.txt", "r") as f:
text = f.read()
text = text.replace("\r\n", "")
text = text.replace("\n", "")
text = text.replace("\u3000", "")
text = m.parse(text)
print(text)
labels, probs = cls.predict(text.strip(), k=10)
for label, prob in zip(labels, probs):
print(label, prob)
cls.predict(text.strip(), k=10)のk=10は、予測したカテゴリのTOP10を表示するという意味です。kを3にした場合はTOP3が表示されます。
Page 14 of 33.
[添付ファイル]
お問い合わせ

すぺぺぺ
自己紹介
本サイトの作成者。
プログラムは趣味と勉強を兼ねて、のんびり本サイトを作っています。
フレームワークはdjango。
ChatGPTで自動プログラム作成に取り組み中。
サイト/ブログ
https://www.osumoi-stdio.com/novel/