843 views
入力が3チャンネル、出力が1チャンネルの場合
まずはテストに使用したコードを以下に記す。
# coding:UTF-8
import numpy as np
import torch
import torch.nn as nn
def conv_test_net():
number_net = nn.Sequential(
nn.Conv2d(3, 1, 3, padding=1),
)
return number_net
if __name__ == '__main__':
# 3チャネル 3×3の画像データを1枚作成
virtual_img = [
[
[
[0,0,0],
[0,1,0],
[0,0,0]
],
[
[0,0,0],
[1,0,0],
[0,0,0]
],
[
[0,1,0],
[0,0,0],
[0,0,0]
],
]
]
t = torch.tensor(virtual_img, dtype=torch.float)
net = conv_test_net()
conv = net[0]
print("[weight]")
print(conv.weight)
print("[bias]")
print(conv.bias)
y = net(t)
print(y.size())
print(y)
前ページのコードから、10行目のコンボリューション層の入力を3チャンネルに、18行目の画像のチャンネルを3チャンネルに変更した。
後は同じである。
実行結果を以下に記す。
[weight]
Parameter containing:
tensor([[[[ 0.1244, 0.1801, -0.0381],
[-0.1907, -0.0382, -0.0145],
[ 0.0761, 0.0338, -0.1086]],
[[ 0.1200, -0.0156, -0.0790],
[ 0.0417, 0.0536, 0.1589],
[-0.1631, 0.1661, -0.1590]],
[[-0.1542, 0.1454, -0.1490],
[ 0.1260, 0.1859, -0.1836],
[ 0.1000, -0.0720, 0.0474]]]], requires_grad=True)
[bias]
Parameter containing:
tensor([0.0105], requires_grad=True)
torch.Size([1, 1, 3, 3])
tensor([[[[-0.1156, 0.0671, 0.2126],
[-0.0993, 0.1594, -0.3344],
[-0.0432, 0.3107, 0.1349]]]], grad_fn=<MkldnnConvolutionBackward>)
コンボリューション層は3枚のフィルター、画像は3チャンネル、出力は1チャンネルである。
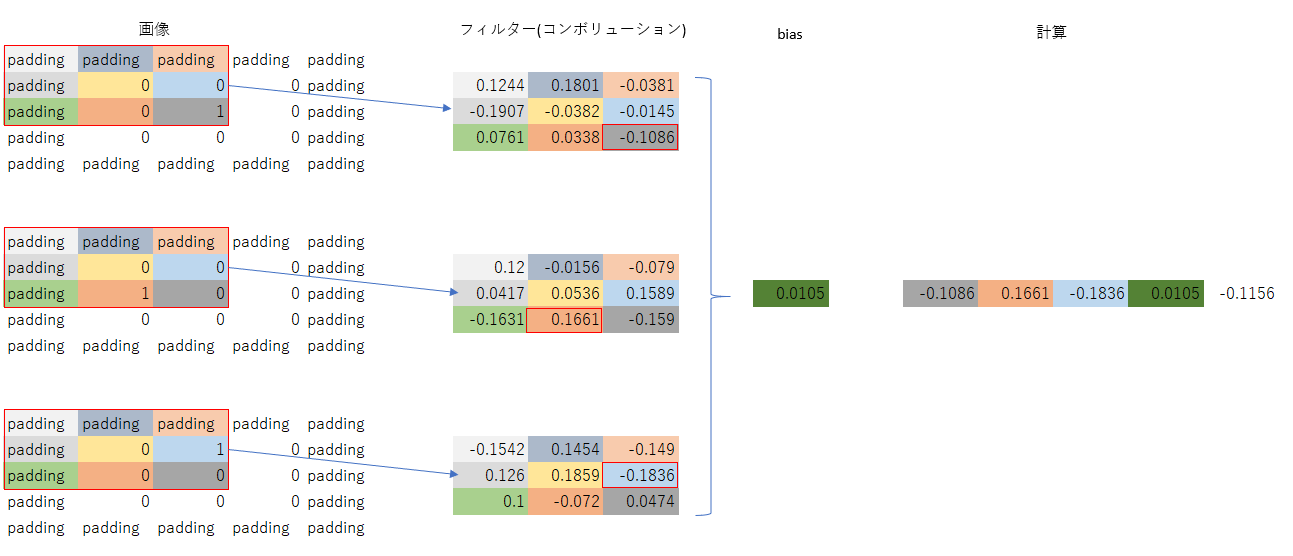
出力の1行1列目の計算は上図のようになり、画像の値が1になっている色分を計算すると、
-0.1086+0.1661+-0.1836+0.0105(bias)=-0.1156
つまり、入力層の数と画像チャンネル同士を掛けて、得られた結果をすべて足し合わせている。biasは最後に1回加算している。
Page 8 of 33.
[添付ファイル]
お問い合わせ

すぺぺぺ
自己紹介
本サイトの作成者。
プログラムは趣味と勉強を兼ねて、のんびり本サイトを作っています。
フレームワークはdjango。
ChatGPTで自動プログラム作成に取り組み中。
サイト/ブログ
https://www.osumoi-stdio.com/novel/