197 views
transformerを理解するためのロードマップ
| トピック | 概要 |
|---|---|
| Attentionとは? | 「重要な単語に注目する」仕組み。 特に Scaled Dot-Product Attention を理解しよう。 |
| Multi-head Attention | 複数の視点からAttentionをとる工夫。 |
| Positional Encoding | 順番のないベクトルに「単語の位置情報」を与える技術。 |
| Encoder-Decoder構造 | Transformerの全体設計:エンコーダが意味を抽出、デコーダが生成する。 |
| Masking | デコーダが未来の単語を見ないようにする処理。 |
| Layer Normalization & Residual | 学習を安定させる工夫。 |
Scaled Dot-Product Attention
transformerモデルの心臓部とも言えるのが「Attention機構」。中でも、最も基本となるのが Scaled Dot-Product Attention です。本章では、その仕組み、なぜ必要なのか、どのように計算されるのか、そして実際のPyTorchコードまでを丁寧に解説していきます。
Attentionの目的
人間が文章を読むとき、文全体の中から重要な単語や情報に"注意"を向けます。Attention機構は、これを数式とベクトル操作で模倣する仕組みです。
例えば、「私は昨日、友達と映画を見に行きました。」という文に対して、「誰と行ったの?」と問われれば、「友達」に注意を向ける必要があります。Attentionはこのように、入力内の"どの部分が重要か"をスコアで表し、重みづけして情報を抽出します。
Scaled Dot-Product Attention
数式で表すと次のようになります:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V
ここで、
- Q: Query(検索するベクトル)
- K: Key(比較されるベクトル)
- V: Value(出力されるベクトル)
- d_k: Keyの次元数(スケーリング係数)
この数式の意味は、
1. QueryとKeyの類似度を内積で計算(どれだけ"似ているか"を数値化)
2. スケーリングして正規化(数値が大きすぎるとsoftmaxが効かなくなる)
3. softmaxで重みを決める("どこにどれだけ注意するか"を決定)
4. Valueをその重みで足し合わせて出力(文脈を反映した情報を抽出)
🔍 注目するポイントが分かる理由
QueryとKeyの内積(QK^T)は、ベクトルの類似度を示す尺度です。Queryは「何を知りたいか?」という視点で、Keyは「各単語が何を表しているか?」を示すベクトルです。
例えば:
Query:「人物に注目したい」
Key:「この単語は人物を意味する」
この場合、QueryとKeyの内積が大きくなり、softmaxを通じてその単語に高い注意が向きます。
🔢 具体例
import torch
import torch.nn.functional as F
q = torch.tensor([[1.0, 0.0]]) # 人物に注目
k = torch.tensor([[1.0, 0.0], [0.0, 1.0]]) # 「友達」と「昨日」
scores = torch.matmul(q, k.T) # → tensor([[1.0, 0.0]])
weights = F.softmax(scores, dim=-1) # → tensor([[0.7311, 0.2689]])
以下の図は、QueryとKeyのベクトルの関係を2次元平面で示したものです:
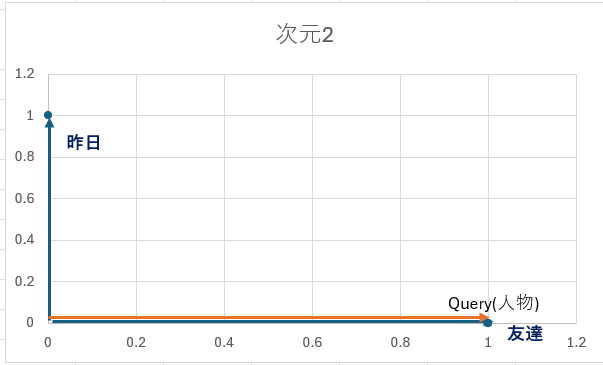
Queryは「人物に注目したい」という意味を持つベクトル [1, 0]
Key1(友達)も [1, 0] で、Queryと完全に同じ方向 → 内積は最大(=1.0)
Key2(昨日)は [0, 1] で、Queryと直角 → 内積は0.0(関連がない)
このように、内積によって「どれだけ似ているか」が数値として現れ、softmaxを通じて注意の重みが決まります。
→ 「友達」に約73%の注意が向く。これが「注目するポイントが分かる」仕組みです。
なぜ"スケーリング"するのか?
QueryとKeyの内積(QK^T)は、入力の次元数が大きくなると値が非常に大きくなり、softmaxの出力が極端に偏ってしまいます。これにより、勾配がほぼゼロになり、学習がうまく進まなくなることがあります。
具体的な例
import torch
import torch.nn.functional as F
# 小さい次元(4次元)
q = torch.ones(1, 4)
k = torch.ones(1, 4)
score = torch.matmul(q, k.T) # → tensor([[4.]])
# 大きい次元(512次元)
q_large = torch.ones(1, 512)
k_large = torch.ones(1, 512)
score_large = torch.matmul(q_large, k_large.T) # → tensor([[512.]])
# softmaxをかけるとどうなる?
scores = torch.tensor([[512.0, 0.0]])
weights = F.softmax(scores, dim=-1)
print(weights) # tensor([[1.0000, 0.0000]]) → ほぼ1点にしか注意が向かない
# スケーリング後(sqrt(512) ≈ 22.6)
scaled_scores = scores / torch.sqrt(torch.tensor(512.0))
scaled_weights = F.softmax(scaled_scores, dim=-1)
print(scaled_weights) # tensor([[0.9895, 0.0105]]) → より滑らかな分布になる
このようにスケーリングを行うことで、softmaxの出力が極端に偏らず、複数の情報に注意を分散させることができます。その結果、勾配も適度に保たれ、学習が安定します。
計算ステップの流れ
- スコア計算:
QK^Tを計算し、\sqrt{d_k}で割る - softmaxで正規化: スコアを確率分布に変換(=どこに注意を向けるか)
- Valueとの重み付き和: softmaxの重みに従って
Vを加重平均
この結果、Queryごとに重要なKeyに対応するValueが強調された出力が得られます。
PyTorchによる実装
以下に、最小構成の Scaled Dot-Product Attention の実装を示します。
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(q, k, v, mask=None):
d_k = q.size(-1)
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn = F.softmax(scores, dim=-1)
output = torch.matmul(attn, v)
return output, attn
使用例:
# シーケンス長 = 3、埋め込み次元 = 4
q = torch.tensor([[[1.0, 0.0, 1.0, 0.0],
[0.0, 1.0, 0.0, 1.0],
[1.0, 1.0, 1.0, 1.0]]]) # shape: (1, 3, 4)
k = torch.tensor([[[1.0, 0.0, 1.0, 0.0],
[0.0, 1.0, 0.0, 1.0],
[1.0, 1.0, 1.0, 1.0]]])
v = torch.tensor([[[10.0, 0.0, 0.0, 0.0],
[0.0, 10.0, 0.0, 0.0],
[5.0, 5.0, 0.0, 0.0]]])
output, attn = scaled_dot_product_attention(q, k, v)
print("出力:", output)
print("Attention重み:", attn)
この例では、QueryとKeyが完全に一致している箇所は内積が最大になるため、そこに強い注意が向きます。出力には、Valueが加重平均された結果が反映され、Attentionの効果が数値として確認できます。
まとめ
Attentionは、情報の重要度をスコアで評価し、意味のある情報を抽出するための仕組みです。TransformerやBERT、GPTなど、現代のNLPモデルの基盤となっている技術です。
次回は、このAttentionを複数組み合わせた「Multi-Head Attention」について解説する予定です。お楽しみに!
Page 30 of 33.
[添付ファイル]
お問い合わせ

すぺぺぺ
自己紹介
本サイトの作成者。
プログラムは趣味と勉強を兼ねて、のんびり本サイトを作っています。
フレームワークはdjango。
ChatGPTで自動プログラム作成に取り組み中。
サイト/ブログ
https://www.osumoi-stdio.com/novel/