1865 views
深さ優先ってなに?
深さ優先探索は、探索対象となる木の最初のノードから、目的のノードが見つかるか子のないノードに行き着くまで、深く伸びていく探索である。その後はバックトラックして、最も近くの探索の終わっていないノードまで戻る。非再帰的な実装では、新しく見つかったノードはスタックに貯める(Wikipediaより)。
つまり、こんな感じ。
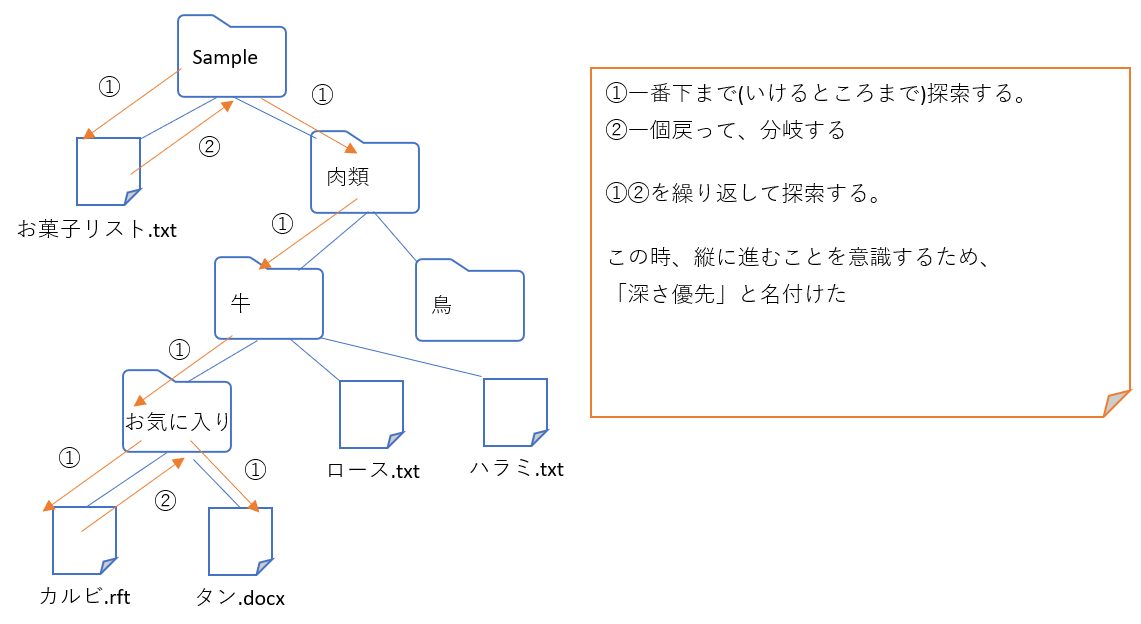
実装_再帰を使う
深さ優先の探索を実装していきます。
本項では、再帰を使った実装方法を記す。
(以前実装したものと同じコードです。わかる方はすごい。)
コード
import os
basePath = os.path.join(os.path.join(os.environ['USERPROFILE']), 'Sample')
baseDir = os.listdir(path = basePath)
def searchDir(dir,path,cnt):
j = 1
space = ' '
while j <cnt :
space +=' '
j += 1
for i in dir:
try:
newPath = path + '//' + i
newDir = os.listdir(path = newPath)
print(space + i)
searchDir(newDir,newPath,cnt+1)
except:
print(space + i)
pass
searchDir(baseDir,basePath,1)
出力

実装_スタック
深さ優先のアルゴリズムはスタックを使っても実装できる。
せっかくなので実装してみた。
コード
import os
# ベースとなるパスとパスを入れておくリスト
basePath = os.path.join(os.path.join(os.environ['USERPROFILE']), 'Sample')
baseDir = os.listdir(path=basePath)
#検索対象のファイル
target = "ハラミ.txt"
#スタック(スタックにはpathを保存する)
stack = []
# 最初に取得できるフォルダをスタックに保存する
for i in baseDir:
path = basePath + '\\' + i
stack.append(path)
print('検索対象のファイル名:', target)
# フォルダ取得
def searchDir(path):
try:
# 子があるとき
# 取得したフォルダ(複数)を
matchDirs = os.listdir(path=path)
for i in matchDirs:
# スタックにpathを入れる
newPath = path + '\\' + i
stack.append(newPath)
except:
# 子がないとき
return None
while stack:
targetPath = stack.pop()
print('検索対象:', targetPath)
if (targetPath.count(target) == 0):
searchDir(targetPath)
else:
print("見つかりました")
print("答え:", targetPath)
break
if not stack:
print("見つかりませんでした")
出力
見つかったとき

見つからないとき

探索順
探索の順番は下の通りになっている。
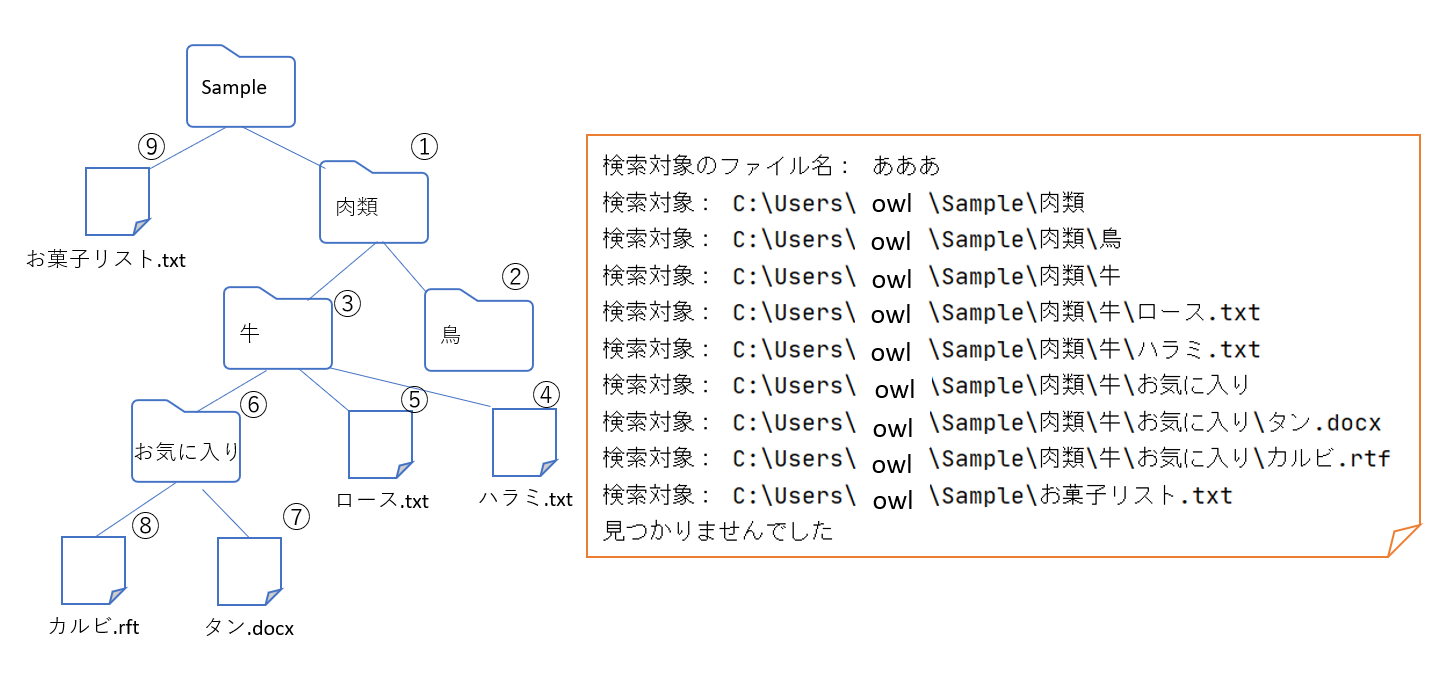
確かに縦検索して上に戻ってまた縦検索して,,,,
ってなってるわ
Page 3 of 5.
[添付ファイル]
お問い合わせ

owl
自己紹介
駆け出しエンジニア
だいたいweb系をかじってる
最近ちょとブロックチェーンに興味出てきた